Four Layers of Hell: How ChatGPT Detects Bots
Sampriti Saha
·May 3, 2026
A deep dive into the layers of bot detection protecting ChatGPT, from TLS fingerprinting to React state attestation, and why the reverse engineering community has been chasing a stable solution for three years.
It was a Wednesday afternoon, drowsiness was hitting while I was correcting endless OS assignments of my juniors. I was sipping coffee hoping to shake off the lethargy (and boredom of not building cool projects or thinking about cool ideas TwT). I had 60+ assignments to correct so like any other human with access to an LLM account, I was using ChatGPT to save me from spending forever going through individual answers while looking out for their terminal output containing their own identifiers (not gemini's, the irony of life). Mind you, I'm a broke(?) college student who can't really afford their paid API key to automate it further. So it was just me manually putting the first prompt: "This is the Rubrics, keep it in mind and correct the individual submissions I give you henceforth", followed by copy pasting the text or attaching the pdf and sending out the message one after the other.
I was bored and frustrated out of my mind wondering why I couldn't just create an extension/ automation queuing mechanism where I dumped in the system prompt and the folder with all the submission pdfs so that, once a response was sent the output could be pushed into an output queue while the top of the input queue was pushed in as a new message to the Web Interface.
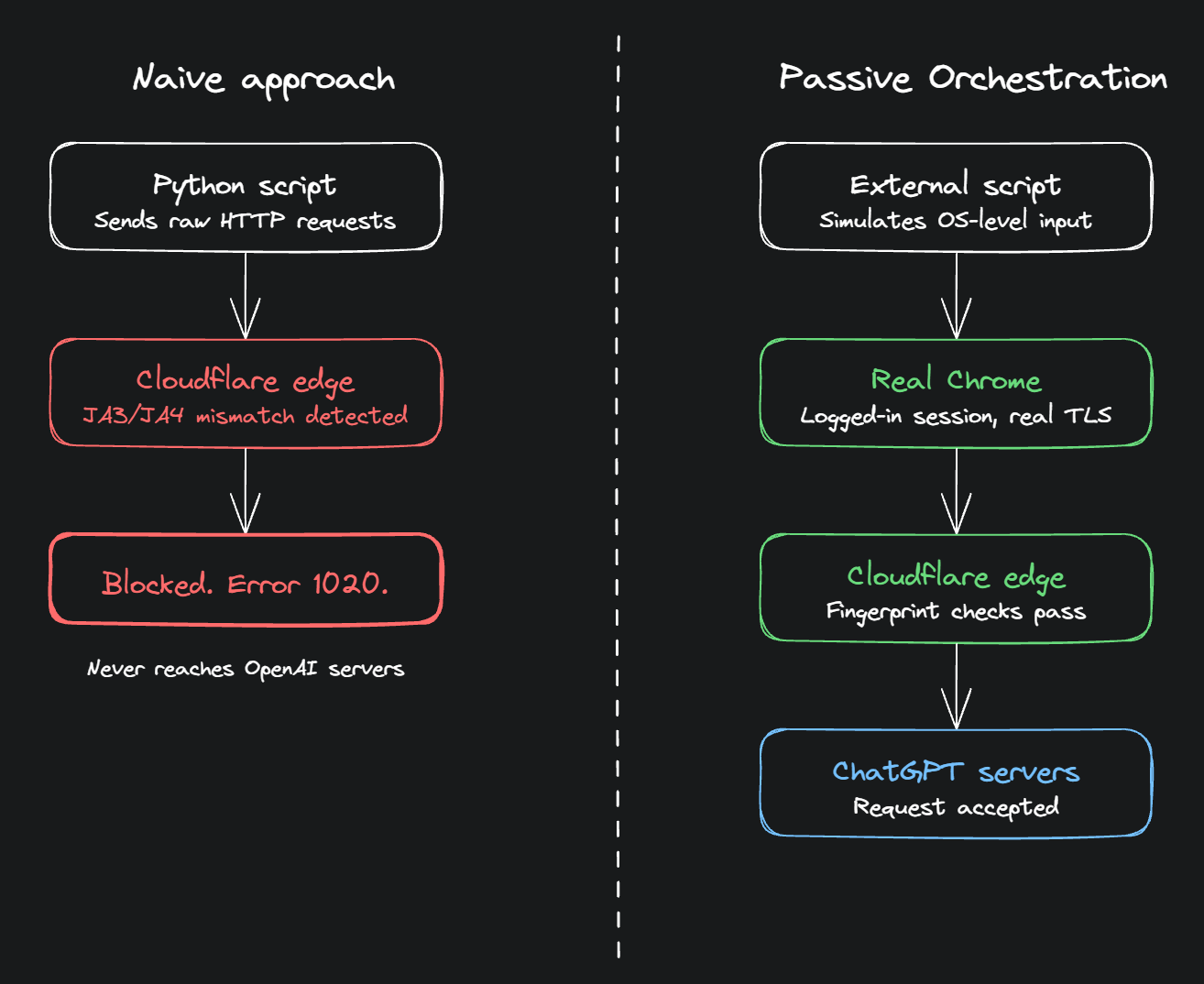
To be fair, I did know that there was some form of bot detection in place that prevents certain browser automations. But here's the thing, I wasn't thinking of faking requests through a Python script or spoofing headers or pretending to be a browser. My idea was simpler than that: just use my actual browser. Keep myself logged in, let Chrome handle everything it normally handles, and just have an external script orchestrate what gets typed and when. Let's call this Passive Orchestration. Cloudflare sees real Chrome because it IS real Chrome. My logged-in session is my logged-in session. Isn't it just routing requests through my actual web interface + human-like timeouts at that point?
But I didn't let myself sit in that overconfidence for too long. There are tons of smart people out there so how is it possible that such a thing has not been done on a large scale and how would OpenAI stay quiet if it was this easy.
So I started digging. I tried understanding what the Reverse Engineering Community had to say about this and all the public information available about the possible layers of security placed in to make this "not such an easy task". What I found was considerably more humbling than I expected.
A note before we get into it: a significant portion of what follows draws on community reverse engineering research rather than official documentation from OpenAI or Cloudflare. OpenAI does not publicly document its bot detection internals, and Cloudflare documents the existence of its mechanisms without detailing their implementation. Where claims come from reverse engineering, particularly the Buchodi research on Turnstile bytecode and the Sentinel header structure from projects like gin337/ChatGPTReversed and leetanshaj/openai-sentinel, I've tried to flag it. Treat those specifics as "very likely approximately correct" rather than vendor-confirmed fact. The overall shape of the defense stack is well-evidenced. The fine-grained implementation details are the community's best current picture.
The Idea Seems Solid. So Why Hasn't Everyone Done This?
On the surface, routing everything through my actual browser seemed airtight. I'm not faking anything: real Chrome, real session, real fingerprints, real Cloudflare clearance. The bot detection has nothing to grab onto because there's nothing fake to detect. The script is just sitting in the background telling the browser what to type and when.
Browser orchestration as a concept is well-trodden. The question isn't whether controlling a browser programmatically is possible. It clearly is. The question is how you do it, because the choice of mechanism turns out to matter enormously. And that's where it gets interesting.
Layer One: The Browser Betrays You, But Only If You Let It
The classic failure mode here is reaching for Playwright or Puppeteer. The moment either of those attaches to a Chrome instance, Chrome changes. Subtly, but detectably.
The most obvious tell: navigator.webdriver gets set to true. This is a standard WebDriver property that exists specifically to indicate browser automation. Cloudflare checks it. OpenAI's Sentinel checks it. Any halfway serious bot detection checks it. Beyond that, Chrome DevTools Protocol, the mechanism Playwright uses to actually control the browser, leaves artifacts: global variables get injected (window.__playwright__binding__, CDP-specific properties on the Error object), JavaScript execution timing differs subtly from a human-driven session, and permission APIs like Notification.permission and navigator.permissions.query return inconsistent states that only appear in automated contexts.
Tools like Patchright and camoufox exist specifically to patch these artifacts out, but at that point a "simple orchestration script" has grown a dependency on a stealth browser framework just to get past the first layer of detection.
But here's the thing: Passive Orchestration doesn't go anywhere near CDP. If the orchestration layer operates at a higher level, simulating system input rather than hooking into browser internals, Chrome is never aware it's being automated. No WebDriver protocol, no injected globals, no CDP connection. The browser just thinks a human is typing. A Chrome extension reading the DOM and dispatching input events, or an external script using system-level input simulation, sidesteps this entire class of detection. The browser fingerprint stays clean because nothing touched it.
So Layer One is largely not an issue for Passive Orchestration. The walls that actually matter are different ones.
Layer Two: Cloudflare Is Reading My React App
This is the one I genuinely did not see coming.
Cloudflare's Turnstile, the successor to the "I am not a robot" checkbox, does something unusual on ChatGPT specifically. It delivers an encrypted bytecode program to the browser that gets executed locally. When a researcher named Buchodi decrypted 377 of these programs in March 2026, he found that among the 55 properties being checked, three of them were reading the internal state of ChatGPT's React application directly: __reactRouterContext, loaderData, and clientBootstrap.
These properties only exist after ChatGPT's frontend has fully loaded and the React app has hydrated. Cloudflare is essentially demanding proof that the ChatGPT web app actually ran, not just that there's a browser present, not just that it looks like Chrome, but that the specific application rendered successfully in that specific session.
For Passive Orchestration, this is not an issue. The real ChatGPT frontend runs in a real browser, the React app hydrates normally, and those properties exist. The Turnstile program finds what it's looking for and produces a valid token. But it illustrates how deep the verification goes, and why any approach that tries to shortcut the browser entirely, raw HTTP requests, a headless browser that skips JS execution, anything that doesn't actually boot the real app, falls apart completely at this layer.
(The React state attestation finding comes entirely from Buchodi's March 2026 reverse engineering write-up. It's the most novel claim in this post and the least independently corroborated. The Cloudflare Turnstile documentation confirms the general capability, proof-of-work, browser-quirk probing, SPA-aware deferred execution, but does not confirm the specific properties checked on ChatGPT.)
Layer Three: The Request Itself Has to Carry Proof
Even with a clean browser fingerprint, every single message sent to ChatGPT has to carry a set of tokens in its request headers that prove it came from a legitimate, freshly-loaded session. This is where OpenAI's own challenge service, separate from Cloudflare entirely, comes in.
Before a message hits /backend-api/conversation, the frontend quietly hits another endpoint: /backend-api/sentinel/chat-requirements. The server hands back a seed and a difficulty value, along with a demand: compute a SHA3-512 proof-of-work by hashing the seed together with properties of the actual browser environment, things like screen dimensions, timezone, CPU core count, and hardware concurrency. Keep iterating a counter until the resulting hash matches the difficulty mask, then send the solution in a header called openai-sentinel-proof-token with every message.
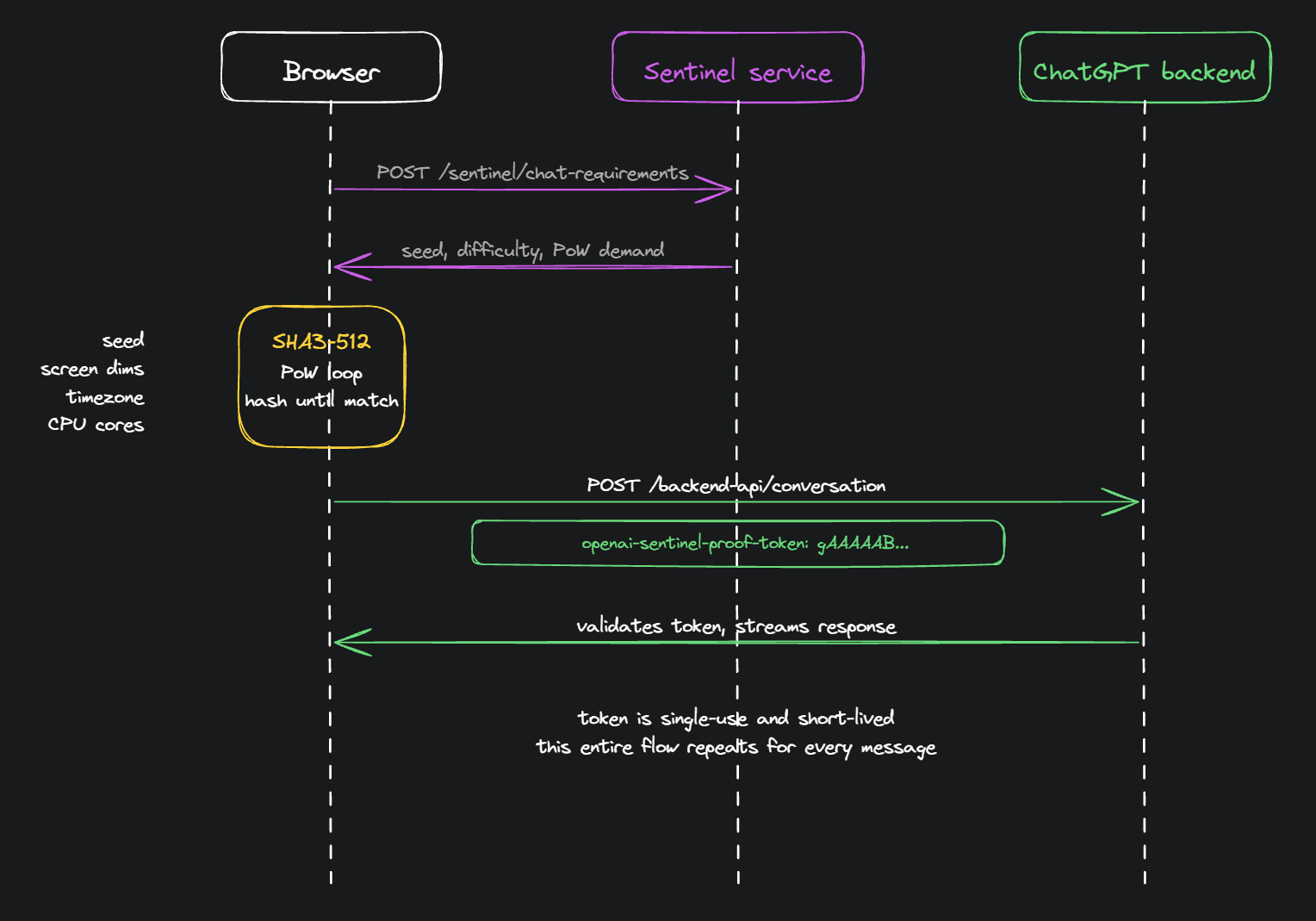
For Passive Orchestration, this is actually fine. Since the real ChatGPT frontend runs in a real browser, this entire flow happens automatically. The browser computes the proof-of-work the same way it would for any human user. No interception, replaying, or injection needed. The real frontend handles it.
(This mechanism is documented by community reverse engineering projects, specifically gin337/ChatGPTReversed, leetanshaj/openai-sentinel, and lanqian528/chat2api, not by OpenAI directly.)
The full decryption, all 377 programs, the two-stage XOR scheme, the complete list of 55 properties, is documented in Buchodi's original write-up. If you want to go deeper on how exactly this bytecode works, that's the place to go. It's a genuinely impressive piece of reverse engineering.
Layer Four: The Pattern Is the Problem
Here's where Passive Orchestration actually hits a wall.
Even if every individual request looks perfectly human, real browser, real fingerprints, real React state, valid proof-of-work, OpenAI's backend is watching patterns at the account level. Sixty messages in a session with consistent inter-message timing, no idle periods, no tab switching, no going back to edit a previous message, no random pauses that I'd naturally take when reading a long response before sending the next one. That raises a question: is the user truly human?
Human behavior is irregular. Automated behavior, even with sleep(random.uniform(3, 8)) calls, has a statistical signature. The timing distribution looks different. The absence of any "oops, let me fix that" moments looks different. The fact that every single message follows the exact same structure, system prompt, then submission, then submission, then submission, looks different.
OpenAI explicitly lists "sudden spikes in activity" and "inconsistent usage patterns" as triggers for their Suspicious Activity Alert system. At 60 assignments in a single session that's not a spike exactly, but the pattern regularity is. Their published response ranges from routing Plus account to GPT-4o-mini only, to temporary locks, to outright bans.
For my specific use case, 60 assignments, my own account, residential IP, done once, I'd probably get away with it (Did I want to risk it though? 🤔). The system is calibrated against large-scale abuse, not a sleep deprived college student with a grading deadline. But "probably fine this once" is a different answer from "this is a viable general solution."
The Graveyard: acheong08/ChatGPT
The best proof that all of this is real and not theoretical is a GitHub repository.
In December 2022, a developer going by acheong08 published a Python library called revChatGPT. It's worth being clear about what it was doing: not browser orchestration, but raw HTTP requests with a stolen session cookie, replaying calls to /backend-api/conversation directly from a Python script. No real browser involved at all. It worked. It worked so well it accumulated over 20,000 GitHub stars in a matter of months, spawning dozens of derivative projects, browser extensions, VS Code plugins, WeChat bots, Telegram integrations. For a brief window, automating ChatGPT really was as simple as copying a cookie and replaying a request.
Then OpenAI noticed.
What followed was a year-long game of whack-a-mole. Cloudflare bot management got tightened, cf_clearance cookies started being IP and User-Agent bound, so transplanting them stopped working. The maintainer built ChatGPTProxy to inject Cloudflare cookies properly. OpenAI patched the email/password auth flow. The maintainer reverse-engineered Auth0. OpenAI introduced Arkose Labs FunCaptcha for GPT-4, per-message CAPTCHAs, rotate-the-animal, count-the-dice. The community reverse-engineered the Arkose token generation. OpenAI disabled the _puid cookie privileges that gave Plus accounts elevated throughput. The maintainer worked around it. Then OpenAI introduced the Sentinel challenge service, proof-of-work tokens, freshly computed per-message, non-replayable, and that was the one that stuck.
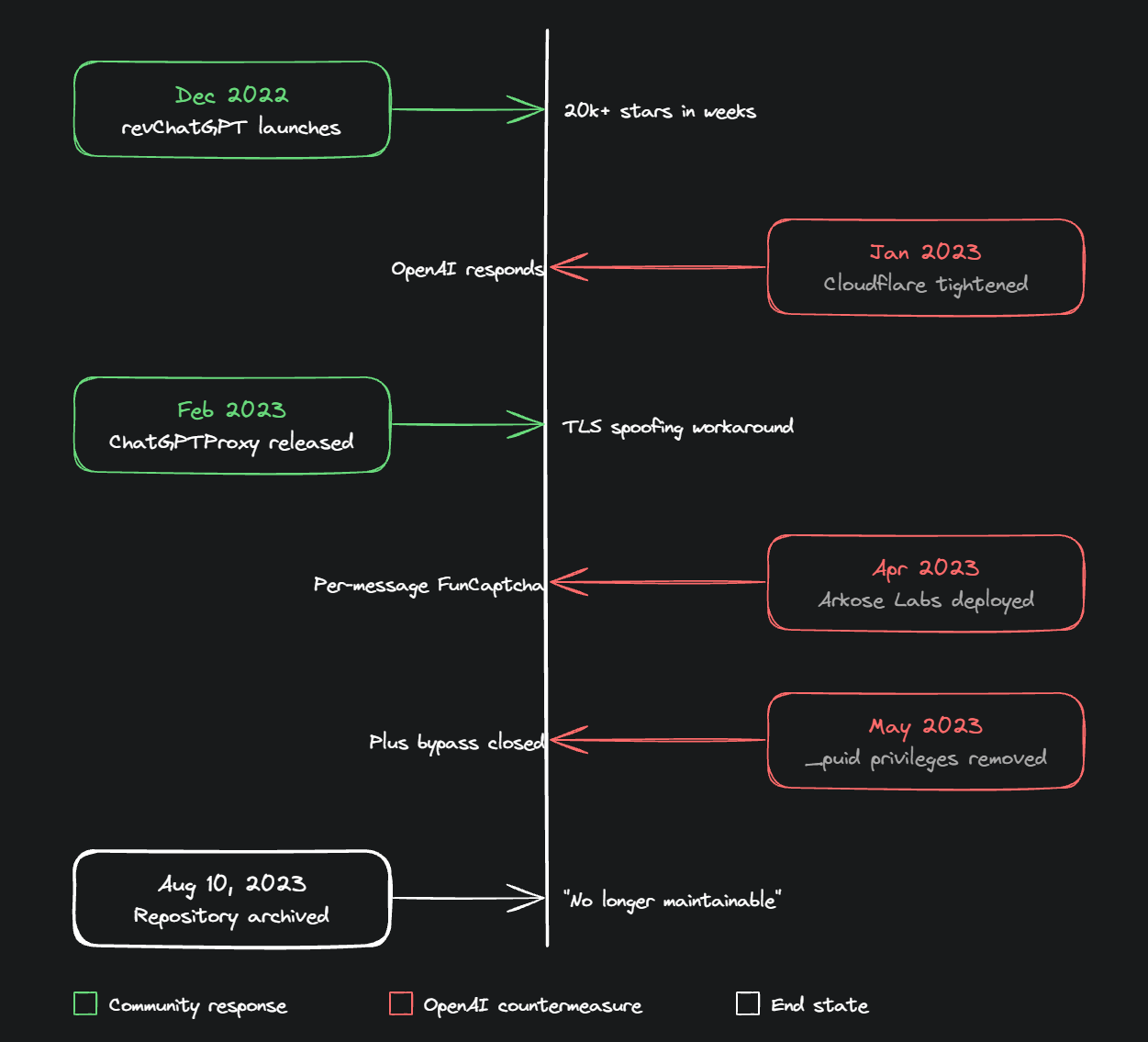
On August 10, 2023, about eight months after the initial release, the repository was archived. The README doesn't explain why in any detail. It just says the project is no longer maintainable against the production stack.
This is instructive. revChatGPT's method, raw HTTP requests without any real browser, was far more exposed to detection than browser orchestration, and it still took OpenAI the better part of a year to fully close the door. The lesson isn't that Passive Orchestration is safe. It's that OpenAI treats any stable automation path as a vulnerability to be patched, and they patch faster than the community can reverse-engineer. The ceiling exists, it just keeps moving.
So What's the Actual Answer?
Passive Orchestration sidesteps the majority of what makes automation detectable, the TLS fingerprinting, the React state attestation, the browser artifact checks. Layers One, Two, and Three largely dissolve. The wall is Layer Four: behavioral pattern detection and the account-level risk model, which are softer and more probabilistic than the cryptographic ones.
The reason it hasn't been done at large scale isn't that it's technically impossible. It's that at scale, the behavioral signal becomes overwhelming, and OpenAI's account-level enforcement catches it. One person automating 60 assignments is noise. A thousand people running the same orchestration pattern against the same endpoints is a signal that gets modeled and blocked.
And that's the honest answer to the question I started with on that Wednesday afternoon. Not "it's impossible" but "it's not worth it at scale, and the closer you look the more layers you find." Understanding how deep it goes, TLS fingerprints, proof-of-work, React state attestation, behavioral analysis. That's what tells you where the actual ceiling is, and why the reverse engineering community has been chasing it for three years without a stable solution.
References
A note on sourcing: a chunk of the technical claims in this post come from community reverse engineering rather than official documentation. The references below are the primary sources. Read them with appropriate skepticism, they're the best available picture, not ground truth.
The acheong08/ChatGPT arms race
- https://github.com/acheong08/ChatGPT (archived)
- https://github.com/acheong08/ChatGPTProxy (archived)
- https://github.com/acheong08/ChatGPT-to-API/issues/81
- https://github.com/acheong08/ChatGPT/issues/1336
- https://archive.org/details/github.com-acheong08-ChatGPT_-_2022-12-11_09-39-23
Buchodi React state attestation research
- https://www.buchodi.com/chatgpt-wont-let-you-type-until-cloudflare-reads-your-react-state-i-decrypted-the-program-that-does-it/
- https://www.penligent.ai/hackinglabs/chatgpt-and-cloudflare-turnstile-what-the-react-state-analysis-actually-shows/
- https://aitoolly.com/ai-news/article/2026-03-30-inside-the-decryption-of-cloudflare-turnstile-how-chatgpt-verifies-react-state-before-allowing-user-1
OpenAI Sentinel / proof-of-work reverse engineering
- https://github.com/gin337/ChatGPTReversed
- https://github.com/leetanshaj/openai-sentinel
- https://github.com/realasfngl/ChatGPT
- https://github.com/lanqian528/chat2api/blob/main/chatgpt/ChatService.py
- https://deepwiki.com/realasfngl/ChatGPT/4.2-token-generation-pipeline
Cloudflare official documentation
- https://developers.cloudflare.com/turnstile/
- https://blog.cloudflare.com/cloudflare-bot-management-machine-learning-and-more/
- https://www.cloudflare.com/application-services/products/bot-management/
Arkose Labs
OpenAI official